
Raw data is important, but what does it really mean, and why is it especially important for global development? For most monitoring and evaluation practitioners and data analysts, raw data is what comes out of a survey before it gets aggregated into high-level information. The raw data is information at the unit level as it is collected, like who was trained, what organizations are donating money, and how much.
Nearly everyone deals with raw data at some point, but not everybody stores it in a way that is useful for subsequent analysis or comparison to other datasets. This is unfortunate considering most of the insight that would affect a project’s overall impact lies in the activity details rather in the high-level numbers. Recognizing this, ACDI/VOCA maintains all raw data in relational databases custom built for our more than 30 projects, whereby the records are valuable end products in and of themselves and not merely means to an end.
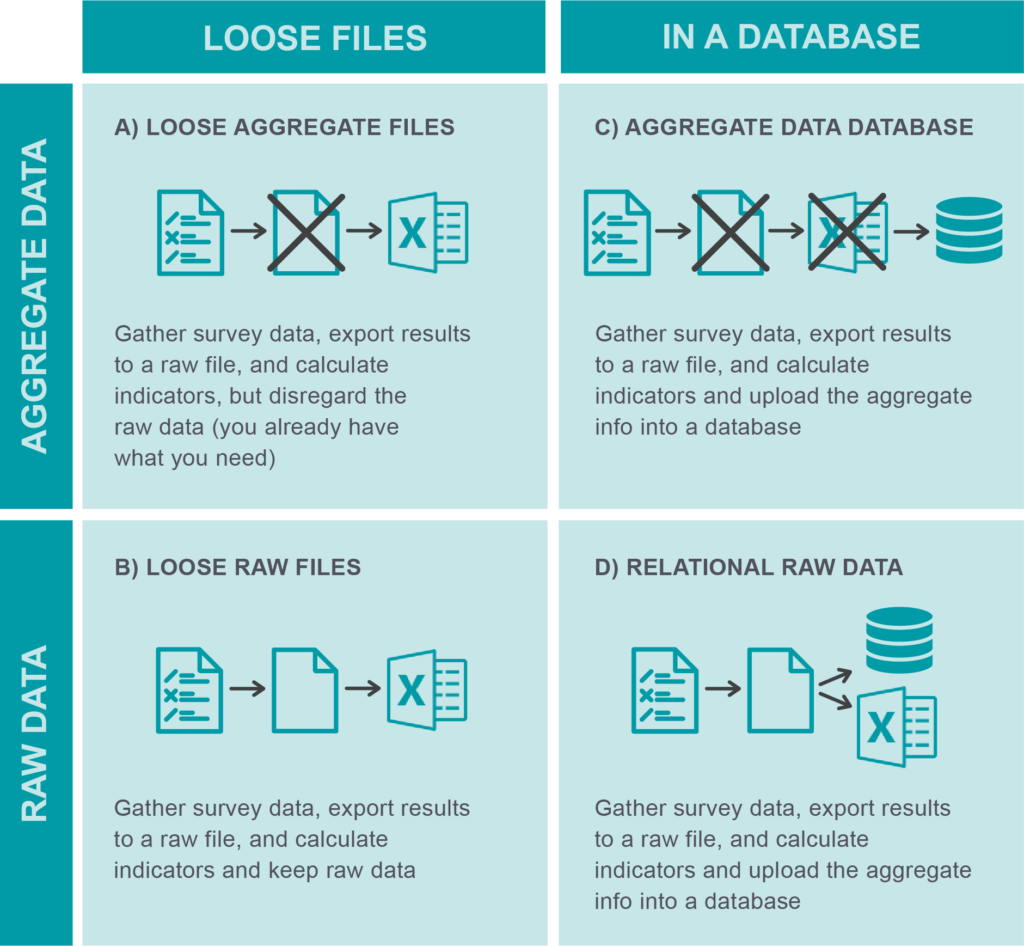
Wait a second…We need a database to utilize raw data? Are all databases relational? The answer to both questions is “not necessarily.” This matrix illustrates raw vs. aggregate data and loose files vs. database:
Before we go any further, let’s loosely define some terms:
- Raw data is the information on individual participants. Example: Ibrahim, male, age 32; Sally, female, age 45; Jaime, male, age 25
- Aggregate is the total (often the count). Example: three people trained
- Disaggregate is the subtotal according to one or more categories. Example: two men trained; one woman trained
With this insight, let’s explore the matrix above. For “A” in the matrix, assume we conduct a survey about food diversity, but we only use the data to calculate the aggregates and disaggregates because we think our donor is only interested in how food diversity varies in each region. The files that came out of the survey may be stuck in the Downloads folder of a project staff member’s computer. This kind of data management practice allows one to answer “What is the status?” and not much more.
In “B,” we thought we might need the raw data itself, so we stored it properly with a useful name and in a location that makes sense. Now at least we can figure out who eats what and compare that to other datasets, such as who received loans to improve their home gardens. This is very important because it lets us answer the question “So what?” However, because there is no deliberate relationship between surveys, stitching them together is going to be challenging, if at all possible. Names might be misspelled, and chances are several people share the same name, which means advanced analyses will be challenging.
Sometimes project staff members think that the way to “do data correctly” is to put things into a database. In no small part, this is due to growing pressure exerted by donors, who are increasingly requiring databases as part of project implementation. Project staff might be tempted to create the scenario in “C,” in which they create a database for their aggregates. In my opinion, this is the least efficient policy of all because, while it does store all the information in one place and allows for a more structured data process, it is limited in functionality because of the lack of raw data. In this case, both the raw data and the analysis file that generated the aggregates could be relegated to a project staff member’s laptop to be lost forever or saved in some archived folder containing thousands of other files — in short, effectively lost.
To avoid all this heartache, ACDI/VOCA stores its data in a relational database. We store raw data in tables that speak to each other by design. This way, when we click on an individual person in the database, we can see every single instance in which our project has intervened with that participant. This includes every corresponding detail, like the date of the intervention, others who participated in it, and more. Because the aggregates and disaggregates are important as well, we can also calculate those, starting from the raw data and following a reproducible approach that maximizes transparency and flexibility.
The important thing to keep in mind, however, is that you can always aggregate raw data, but you can’t split up a total. If all you have saved is “34,000 people trained,” you can’t revert back to the raw data. Watch our video to better understand the advantages of using raw, relational data for your global development projects and check out the full Data Digest blog series.
Comments





